Scrapi Mcp
What is Scrapi Mcp
scrapi-mcp is an MCP server designed to utilize ScrAPI for scraping web pages, providing a powerful and reliable solution for data extraction from various websites.
Use cases
Use cases for scrapi-mcp include scraping product data from e-commerce sites, gathering news articles from online publications, and extracting information from websites with complex structures or restrictions.
How to use
To use scrapi-mcp, you can call its tools such as scrape_url_html or scrape_url_markdown with a URL to retrieve the content in either HTML or Markdown format. An optional API key can enhance usage limits.
Key features
Key features of scrapi-mcp include the ability to scrape content from websites that have bot detection or geolocation restrictions, support for retrieving results in both HTML and Markdown formats, and options for enhanced usage with an API key.
Where to use
scrapi-mcp can be used in various fields such as data analysis, web research, content aggregation, and any scenario requiring automated data extraction from websites.
Clients Supporting MCP
The following are the main client software that supports the Model Context Protocol. Click the link to visit the official website for more information.





Overview
What is Scrapi Mcp
scrapi-mcp is an MCP server designed to utilize ScrAPI for scraping web pages, providing a powerful and reliable solution for data extraction from various websites.
Use cases
Use cases for scrapi-mcp include scraping product data from e-commerce sites, gathering news articles from online publications, and extracting information from websites with complex structures or restrictions.
How to use
To use scrapi-mcp, you can call its tools such as scrape_url_html or scrape_url_markdown with a URL to retrieve the content in either HTML or Markdown format. An optional API key can enhance usage limits.
Key features
Key features of scrapi-mcp include the ability to scrape content from websites that have bot detection or geolocation restrictions, support for retrieving results in both HTML and Markdown formats, and options for enhanced usage with an API key.
Where to use
scrapi-mcp can be used in various fields such as data analysis, web research, content aggregation, and any scenario requiring automated data extraction from websites.
Clients Supporting MCP
The following are the main client software that supports the Model Context Protocol. Click the link to visit the official website for more information.
Content
![]()
ScrAPI MCP Server
![]()


MCP server for using ScrAPI to scrape web pages.
ScrAPI is your ultimate web scraping solution, offering powerful, reliable, and easy-to-use features to extract data from any website effortlessly.
Tools
-
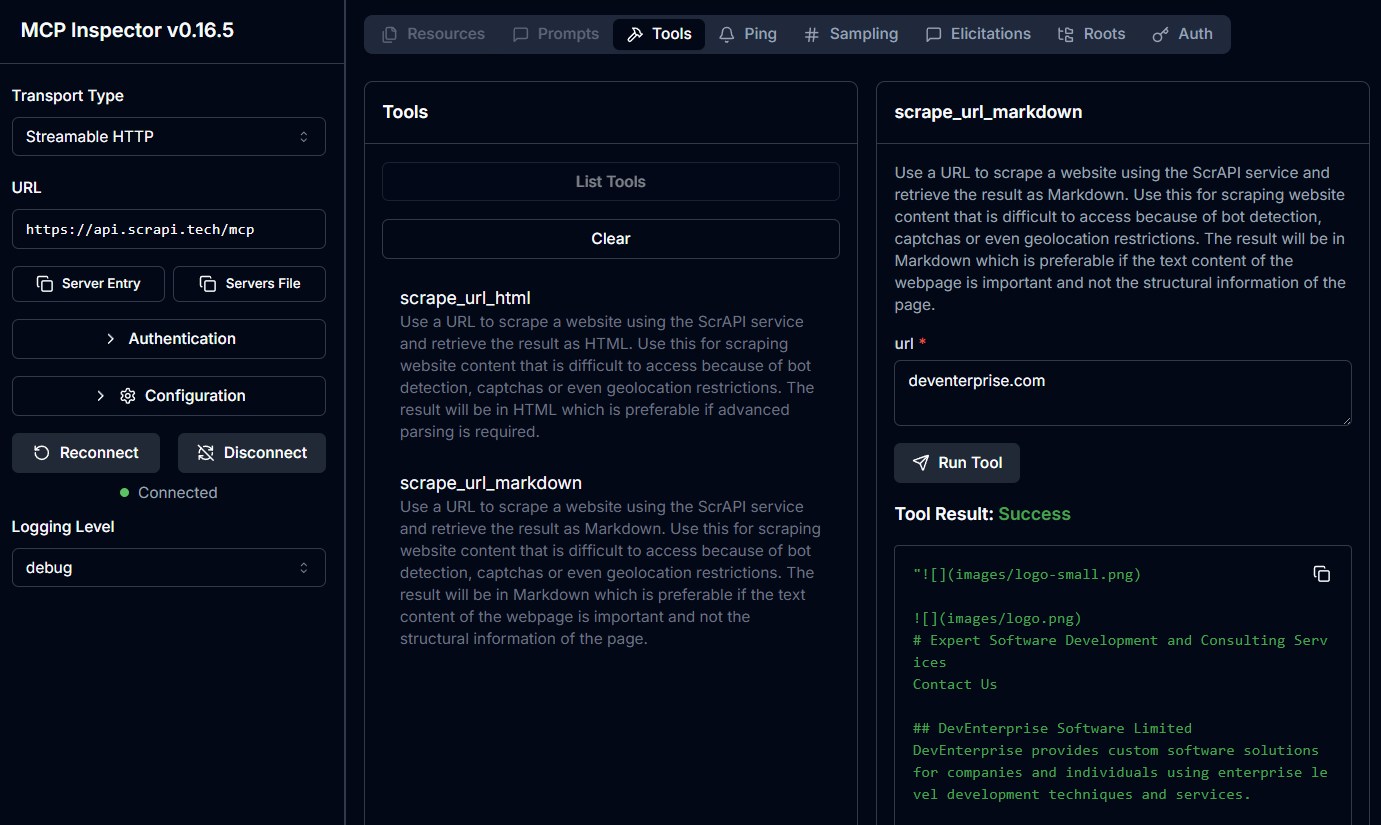
scrape_url_html- Use a URL to scrape a website using the ScrAPI service and retrieve the result as HTML.
Use this for scraping website content that is difficult to access because of bot detection, captchas or even geolocation restrictions.
The result will be in HTML which is preferable if advanced parsing is required. - Input:
url(string) - Returns: HTML content of the URL
- Use a URL to scrape a website using the ScrAPI service and retrieve the result as HTML.
-
scrape_url_markdown- Use a URL to scrape a website using the ScrAPI service and retrieve the result as Markdown.
Use this for scraping website content that is difficult to access because of bot detection, captchas or even geolocation restrictions.
The result will be in Markdown which is preferable if the text content of the webpage is important and not the structural information of the page. - Input:
url(string) - Returns: Markdown content of the URL
- Use a URL to scrape a website using the ScrAPI service and retrieve the result as Markdown.
Setup
API Key (optional)
Optionally get an API key from the ScrAPI website.
Without an API key you will be limited to one concurrent call and twenty free calls per day with minimal queuing capabilities.
Cloud Server
The ScrAPI MCP Server is also available in the cloud over SSE at https://api.scrapi.dev/sse
Cloud MCP servers are not widely supported yet but you can access this directly from your own custom clients or use MCP Inspector to test it. There is currently no facility to pass through your API key when connecting to the cloud MCP server.
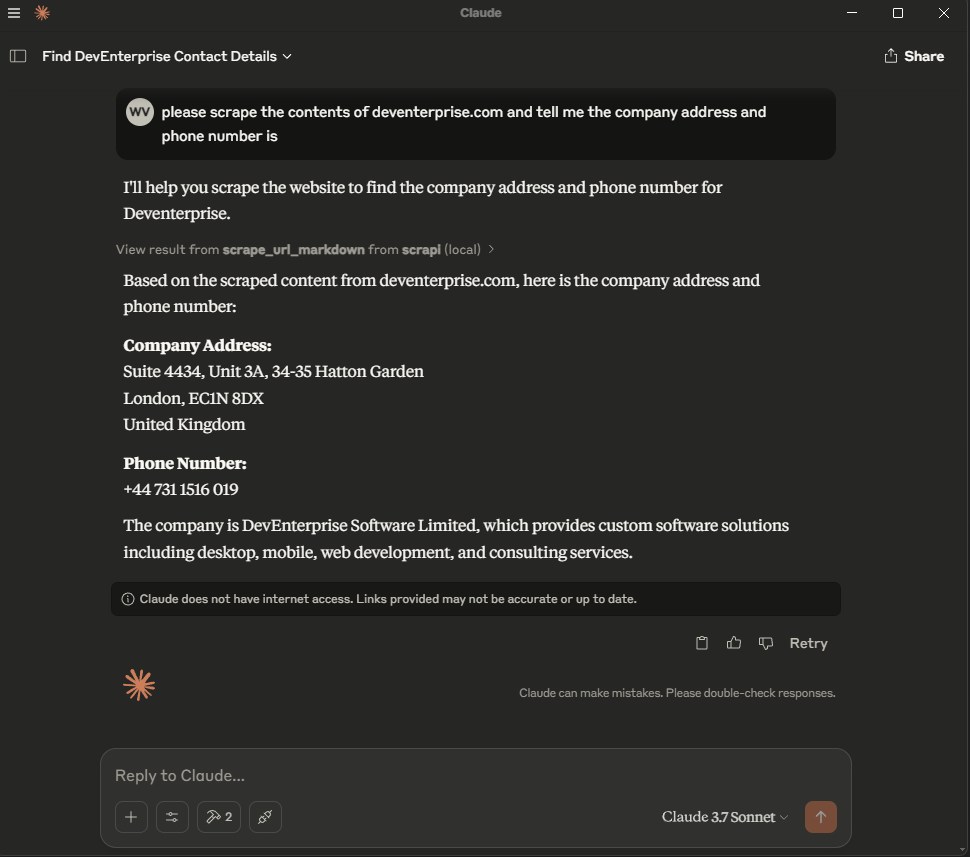
Usage with Claude Desktop
Add the following to your claude_desktop_config.json:
Docker
{
"mcpServers": {
"scrapi": {
"command": "docker",
"args": [
"run",
"-i",
"--rm",
"-e",
"SCRAPI_API_KEY",
"deventerprisesoftware/scrapi-mcp"
],
"env": {
"SCRAPI_API_KEY": "<YOUR_API_KEY>"
}
}
}
}NPX
{
"mcpServers": {
"scrapi": {
"command": "npx",
"args": [
"-y",
"@deventerprisesoftware/scrapi-mcp"
],
"env": {
"SCRAPI_API_KEY": "<YOUR_API_KEY>"
}
}
}
}
Build
Docker build:
docker build -t deventerprisesoftware/scrapi-mcp -f Dockerfile .
License
This MCP server is licensed under the MIT License. This means you are free to use, modify, and distribute the software, subject to the terms and conditions of the MIT License. For more details, please see the LICENSE file in the project repository.
Dev Tools Supporting MCP
The following are the main code editors that support the Model Context Protocol. Click the link to visit the official website for more information.










